
Route53 is the platform you can use inside AWS to manage your DNS. It is simple, solid, cheap, reliable. However, it lacks something very important: backups. If you change your DNS records and mess it up, you cannot revert to the previous version natively. This is about to change. With this AWS Route53 backup tutorial, we will see how to do a backup – all inside AWS!
Note: to get the most out of this AWS Route53 backup tutorial, you should be using Route53 already. Furthermore, some basic knowledge of Python will be helpful.
AWS Route53 Backup Tutorial
The Route53 environment
Whether you are just starting out with Route53 or already have a complex deployment, this post is for you. In fact, the backup solution we are going to apply can digest any Route53 configuration and backup it all.
In this solution, we see how to backup Route53 zones, but you can extend the same concepts to the backup of domains.
Furthermore, all this backup solution is cloud-based and serverless: we can run it inside Amazon without any problem. However, please note it will have some additional costs: the cost of the storage of the backups, and the cost of the execution. Obviously, those costs are minimal.
A place for backups: S3
Like all the backups of any kind, we need tome storage space to store the information we are backing up. We are going to do it the Amazon way, using AWS S3. Even if you are not used it before, just know it is extremely simple. It works like a folder, in which you can create files or subfolders.
Log in into your AWS Console, navigate to the S3 service, and create a new bucket with a name you like. The important thing here, during the creation of the bucket, is to enable versioning. Otherwise, all the backup script will be useless.
If you need more help on how to configure an S3 bucket for versioning, we have a wonderful guide to teach you the basics of S3 (including versioning).
Once you have your bucket ready, we can proceed with the heart of the script: Lambda.
A runner for the AWS Route53 backup: Lambda
Now we know what data to take (Route53 configuration) and where to put it (S3 bucket). We need someone to do that.
This is where AWS Lamba comes it. AWS Lambda is a serverless function product. In other words, you provide some files containing the code to execute, and Amazon just executes them (when you trigger them). You only pay for the execution time. If our backup doesn’t run, we won’t pay for it.
This is perfectly in the spirit of AWS – and cloud in general – and that’s what we are going to do.
AWS Route53 backup function
Creating the Lambda function
The Lambda function is the core of our backup. Is the worker who actually does the backup. To create a new Lambda function, search for the service AWS Lambda, and in it create a new function.
When creating a function, you have several options. Choose to Author from scratch your function, give it a name, and set the runtime to be Python 3.x (3.7 at the time of writing this post).
As an execution role, select to create a new role. This is the set of permissions your function will have. We will have to add to it permission to access Route53 and S3 later.
Once you create your function, you will end up in a basic Python editor where you can manage your function. By default, it contains only one filelambda_function.py
Writing the Lambda function
Instead of a single file, we are going to use two. In one filezone.pylambda_function.pyzone.py
The Zone class
Below, you find the zone.py
import boto3
import json
from datetime import datetime
route53 = boto3.client('route53')
s3 = boto3.resource('s3')
cloudwatch = boto3.client('cloudwatch')
class Zone:
def __init__(self, id):
self.id = id
@staticmethod
def log(zone_id, message, backup_name=None, has_error=False):
print('zone_id="{}" message="{}" backup_name="{}" has_error="{}"'.format(
zone_id,
message,
backup_name,
has_error
))
def get_hosted_zone(self):
"""Get the hosted zone backup"""
try:
return {
'success': True,
'response': route53.get_hosted_zone(Id=self.id)
}
except Exception as e:
self.log(
self.id,
'Error while dumping hosted zone: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}
def get_record_set(self):
"""Get the record set backup"""
try:
return {
'success': True,
'response': route53.list_resource_record_sets(HostedZoneId=self.id)
}
except Exception as e:
self.log(
self.id,
'Error while dumping record sets: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}
def get_tags(self):
"""Get the tags backup"""
try:
return {
'success': True,
'response': route53.list_tags_for_resource(
ResourceType='hostedzone',
ResourceId=self.id
)
}
except Exception as e:
self.log(
self.id,
'Error while dumping tag: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}
def backup(self):
"""Get the full backup"""
hosted_zone = self.get_hosted_zone()
record_set = self.get_record_set()
tags = self.get_tags()
if not hosted_zone['success'] or not record_set['success'] or not tags['success']:
return None
return {
'HostedZone': hosted_zone['response']['HostedZone'],
'DelegationSet': hosted_zone['response']['DelegationSet'],
'ResourceRecordSets': record_set['response']['ResourceRecordSets'],
'Tags': tags['response']['ResourceTagSet']['Tags']
}
@staticmethod
def get_backup_name(id, path, backup):
name = backup['HostedZone']['Name'][:-1] + '-' + id + '.json'
if path is not None:
name = path + '/' + name
return name
def upload_backup(self, bucket, path):
"""Push the full backup to S3"""
backup = self.backup()
if backup is None:
self.log(
self.id,
'Attempted backup failed because there was an error in generating the backup',
has_error=True
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Failure'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': False,
'error': 'No backup was generated'
}
name = self.get_backup_name(self.id, path, backup)
# Check if data has changed since the last backup
obj = s3.Object(bucket, name)
try:
last_backup = json.loads(obj.get()['Body'].read())
if last_backup == backup:
self.log(
self.id,
'Backup suceeded, current configuration is identical to the one already in backup (VersionId={}). No new file was uploaded.'.format(obj.version_id),
backup_name=name
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Success'
},
{
'Name': 'NewUpload',
'Value': 'False'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': True,
'uploaded_new_version': False,
'existing_valid_version': obj.version_id
}
except:
pass
else:
obj.put(Body=json.dumps(backup, indent=4, sort_keys=True))
self.log(
self.id,
'Backup suceeded, configuration changed since last backup and new file was uploaded.',
backup_name=name
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Success'
},
{
'Name': 'NewUpload',
'Value': 'True'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': True,
'uploaded_new_version': True
}
Boto3
The first thing we need to do in our file is getting an instance of AWS APIs. In fact, our function calls the APIs of Amazon to do the backup of Route53. We need to use three AWS APIs:
route53to fetch data from route53s3is needed to upload data into our bucketcloudwatch, to write some logs about the operation of our function
We import them and create three global variables. Global variables may not be the best thing to do, but as this is a very simple function they will do the job.
import boto3
import json
from datetime import datetime
route53 = boto3.client('route53')
s3 = boto3.resource('s3')
cloudwatch = boto3.client('cloudwatch')The constructor
Now, we have to write a constructor for our Zone. To identify a zone, we have to provide its unique ID that AWS associated with the zone. It is unique in all the Amazon world, so it is a good way to get the right zone.
class Zone:
def __init__(self, id):
self.id = id
Logging
Logging is quite important for our script. In fact, the function will check if the backup already present in S3 is identical to the export of route53. If so, it will not create a new version of our file in S3. However, we may want to know if this check actually happens, or if we have had any error. Thus, we will write some logs to Cloud Watch.
We want to write all logs in a way that is standard, easy to read, and easy to parse. To do that, we use a dedicated functionlog()
@staticmethod
def log(zone_id, message, backup_name=None, has_error=False):
print('zone_id="{}" message="{}" backup_name="{}" has_error="{}"'.format(
zone_id,
message,
backup_name,
has_error
))Backup methods
In total, we need to fetch three different items from route53: the hosted zone configuration, the record sets, and the tags. Thus, we create three methods to do exactly that. They will call various AWS APIs and get the JSON data needed. If the call to the API fails, they will None
def get_hosted_zone(self):
"""Get the hosted zone backup"""
try:
return {
'success': True,
'response': route53.get_hosted_zone(Id=self.id)
}
except Exception as e:
self.log(
self.id,
'Error while dumping hosted zone: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}
def get_record_set(self):
"""Get the record set backup"""
try:
return {
'success': True,
'response': route53.list_resource_record_sets(HostedZoneId=self.id)
}
except Exception as e:
self.log(
self.id,
'Error while dumping record sets: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}
def get_tags(self):
"""Get the tags backup"""
try:
return {
'success': True,
'response': route53.list_tags_for_resource(
ResourceType='hostedzone',
ResourceId=self.id
)
}
except Exception as e:
self.log(
self.id,
'Error while dumping tag: {}'.format(str(e)),
has_error=True
)
return {
'success': False,
'error': str(e)
}And, finally, we combine all three results into a single function, that None
def backup(self):
"""Get the full backup"""
hosted_zone = self.get_hosted_zone()
record_set = self.get_record_set()
tags = self.get_tags()
if not hosted_zone['success'] or not record_set['success'] or not tags['success']:
return None
return {
'HostedZone': hosted_zone['response']['HostedZone'],
'DelegationSet': hosted_zone['response']['DelegationSet'],
'ResourceRecordSets': record_set['response']['ResourceRecordSets'],
'Tags': tags['response']['ResourceTagSet']['Tags']
}The backup name
Now, we need to give our route53 backup a name. We could just use the ID of the Zone, but if we have many backups it would be very hard to browse among them manually. So, as name, we use a combination of zone name and unique ID.
To create this name, we have a dedicated function. It will take as input the JSON object extracted from the backup function, the zone ID, and a path, in case we don’t want to put our zone in the root of the bucket.
@staticmethod
def get_backup_name(id, path, backup):
name = backup['HostedZone']['Name'][:-1] + '-' + id + '.json'
if path is not None:
name = path + '/' + name
return nameUploading the backup
Now our Route53 backup tutorial gets interesting. This part of the code snippet contains most of the logic. First, it attempts to obtain a backup, and if that’s in error it writes an error message in CloudWatch.
def upload_backup(self, bucket, path):
"""Push the full backup to S3"""
backup = self.backup()
if backup is None:
self.log(
self.id,
'Attempted backup failed because there was an error in generating the backup',
has_error=True
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Failure'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': False,
'error': 'No backup was generated'
}If instead, the backup was obtained, it identifies the name of the backup files in S3 and creates an object to represent it.
name = self.get_backup_name(self.id, path, backup)
# Check if data has changed since the last backup
obj = s3.Object(bucket, name)It attempts to download the object from S3 and compare it to the one just obtained from Route53. If they are equal, it writes that to CloudWatch, otherwise continue.
try:
last_backup = json.loads(obj.get()['Body'].read())
if last_backup == backup:
self.log(
self.id,
'Backup suceeded, current configuration is identical to the one already in backup (VersionId={}). No new file was uploaded.'.format(obj.version_id),
backup_name=name
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Success'
},
{
'Name': 'NewUpload',
'Value': 'False'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': True,
'uploaded_new_version': False,
'existing_valid_version': obj.version_id
}
except:
passIf we made it this far it means the two backups are different. The function uploads a new version to S3 and logs it.
else:
obj.put(Body=json.dumps(backup, indent=4, sort_keys=True))
self.log(
self.id,
'Backup suceeded, configuration changed since last backup and new file was uploaded.',
backup_name=name
)
cloudwatch.put_metric_data(
Namespace='Network',
MetricData=[{
'MetricName': 'Route53ZoneBackup',
'Dimensions': [
{
'Name': 'Status',
'Value': 'Success'
},
{
'Name': 'NewUpload',
'Value': 'True'
}
],
'Timestamp': datetime.now(),
'Value': 1,
'Unit': 'Count'
}])
return {
'success': True,
'uploaded_new_version': True
}While this may seem a complex script, its job is very simple. Indeed, having a run in various cases and checking the logs in cloud watch will help you understand it better.
lambda_function
Unlike our previous file, lambda_function.py is much more succinct. It wants to know the zone id as
from zone import Zone
import json
def lambda_handler(event, context):
try:
args = json.loads(event['Records'][0]['Sns']['Message'])
except:
args = event
zone = Zone(args['zone_id'])
return {
'statusCode': 200,
'body': json.dumps(zone.upload_backup(args['bucket_name'], args['bucket_path']))
}Save both files, and your lambda function is ready to go.
Overview of the lambda function
If you save your function, AWS will show you a summary of its triggers and resources. A trigger is something that makes the function run, while a resource is something your function use.
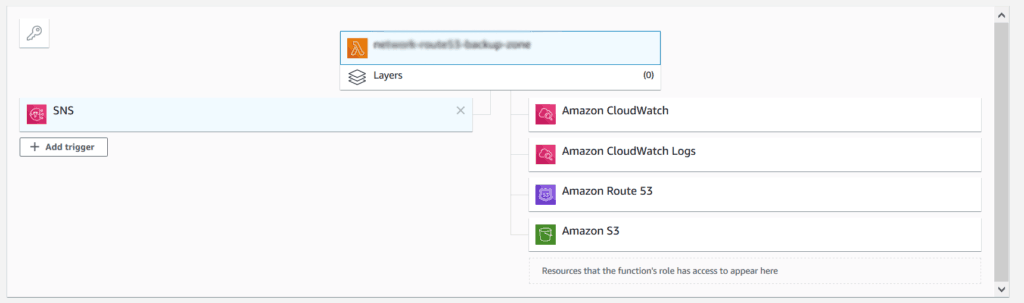
Note that you won’t have any trigger in your function, because you haven’t subscribed it to any SNS stream yet. You can attach this function to either an API, or a SNS stream – this is up to you.
Using SNS may be simpler if you want to quickly test a manual backup. Once you have your stream set, you can publish into it the ID of a zone you wish to backup, and the function will take care of that.
You can also use another Lambda function to write the zone IDs into that stream automatically. In this way, you will have one function doing the backup (this one), and another saying when and what to backup. That’s what I have put in production in an enterprise-grade environment.
IAM Permissions
If you rune your function now, it will not work. By default, in fact, it has no permissions. We need to adjust its role to have the permission it needs. It is outside the purpose of this article to give you a detailed explanation of IAM. Just know that the right production approach would be to give the minimal privilege required. This means it should only access route53 in read-only, and S3 in read-write but for only the bucket where you want to store the backups. On top of that, the function should not have the right to alter the properties of the bucket itself.
Additionally, the function must have the ability to create logs in CloudWatch.
If you are just testing out, you can give your function all permissions in route53, S3, and CloudWatch. Of course, this is not recommended.
Running our AWS Route53 Backup
If you now run your AWS Route53 backup, you will be able to see its results in CloudWatch and S3. For example, in the environment where I have this function backing up all the zones, I can see the following in our bucket.
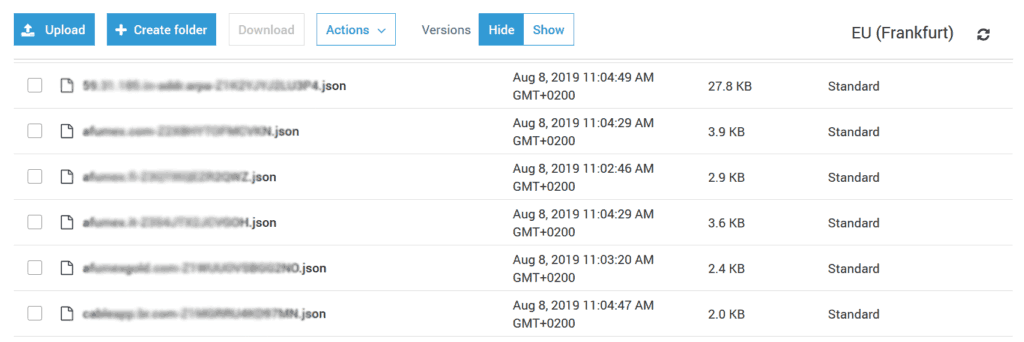
You can download and see the files for yourself in the version you need them. If you need to do a restore, you will have to call the API and provide the three objects stored in each backup: hosted zone details, record set, tags.
Last words on AWS Route53 Backup
In this intense post, we saw how to use AWS tools to create an AWS Route53 backup. Of course, I recommend extending that to a more production-ready solution. Things that may be creat to do include: periodic backup, automatic trigger of backup upon changes, and automated restore, without having to call the API manually.
What do you think of this solution? Does it help you managing your Route53 zones? Let me know in the comments.
