
The application layer is the one that truly makes the difference. This layer is the uppermost of the OSI stack, and it’s the place where the application resides: you can find here protocols that allow you to send and receive emails, surf the web, watch videos and play online games. While the rest of the OSI stack works with the same protocols all the time, in this layer each application has its very own protocol. In this article, we present an overview of the way an application-layer protocol works, then we present the most used ones. Let’s get started!
The application layer
Our world is full of applications. With that, we do not simply mean smartphone apps, but any program that can run on a computer, smartphone, or any other smart device. These programs are the one you use daily to do everything you have to do with your computer. Regardless of the purpose of the application, which can be – for example – sending emails or surfing the web, all the programs have the same goal in mind: they provide a clear interface that you can use to do what you need. But let’s re-write this sentence in a more technical way: instead of providing you an easy interface to send emails, Mozilla Thunderbird provides you an easy interface to use the OSI stack to send emails. Applications interface with human users, take information from them, and re-encode that information in such a way that it can travel over the network and be understood from the other application on the other side. The following picture highlights just that.
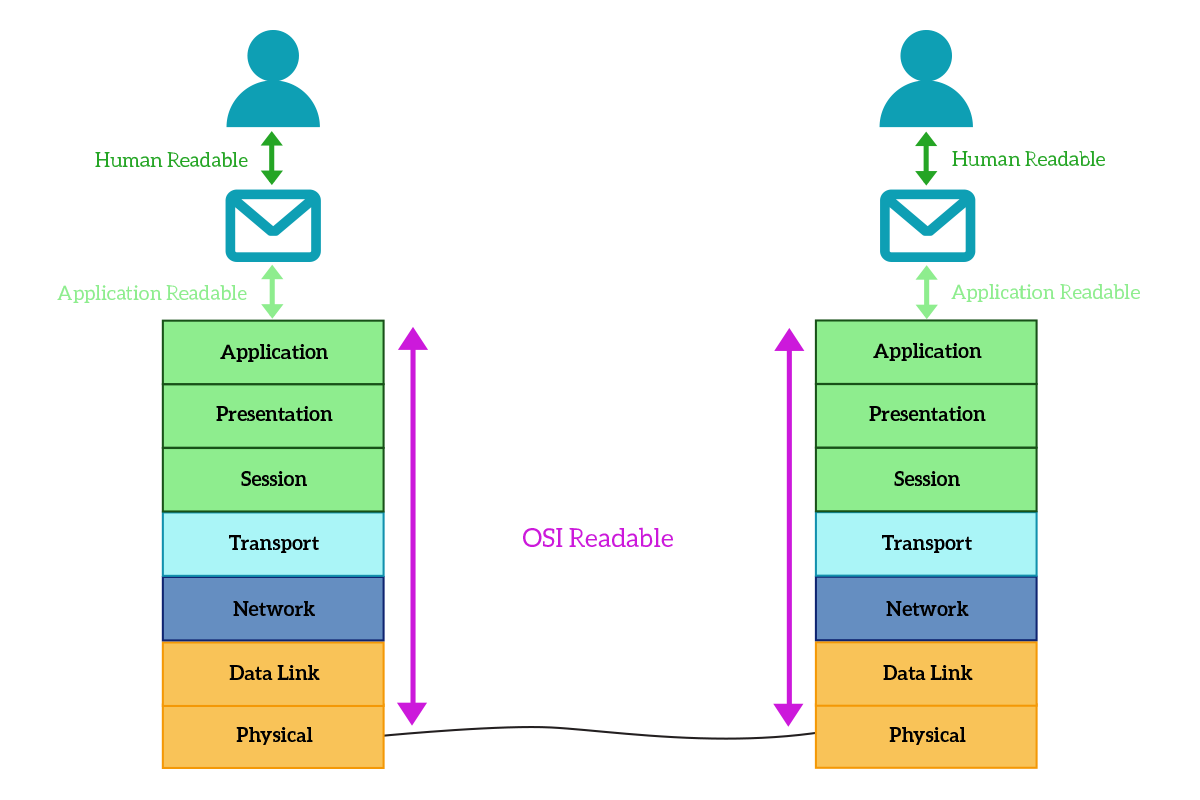
Any application needing network access can craft its own network protocol, provided that all instances of that application will use the same protocol. This results in having a huge variety of protocols working at this layer, with huge differences between one another. However, many applications are standardized and they work with well-known protocols. The features of these protocols are well-documented and available for free online so that you can develop your own application supporting that protocol: this foster application interoperability. In the following sections of this article, we will see what protocols are used to surf the web, send emails, connect to a remote computer and exchange files, and how they work exactly.
Web protocols
All in all, web protocols are the ones allowing you to surf the web. Talking about that, it is mandatory to truly understand the difference between “the Web” and “the Internet”. We can say that the Web is a subset of the Internet: the Internet is the collection of all devices interconnected world-wide, while the Web is the group of devices within the Internet that offer websites and web content. This web content is mainly text pages, images, and video, and the key characteristic that identifies it is that it can be read from the user on-the-fly. It is not like downloading a file and then opening it, surfing the web is about getting the page you are looking for immediately.
HTTP Basics
To achieve this behavior, we use a specific protocol called Hyper-Text Transfer Protocol, shortened as HTTP. The name of the protocol is pretty clear, it allows the transfer of HyperTexts, which are web contents such as text web pages, images, or videos. This transfer is designed with a client-server model, where there is always a device (the client) that makes requests to the other device (the server), with the server that just replies with what asked. HTTP uses TCP at the transport layer, with a random port used by the client and a well-known port used by the server: the port 80 (by default).
Like many application-layer protocols, HTTP is text-based: this means that its header is not composed of fixed-length fields like TCP, UDP or other protocols working at lower layers, but instead, it is made of plain text. Only two types of messages exists in HTTP: Requests, created by the client; and Responses, created by the server. The client opens a TCP connection to the webserver, then sends a plain-text HTTP Request over that connection. Then, the server processes the request and replies with an HTTP Response using the same TCP connection, which is then closed by the server once the entire content is delivered to the client. As in the picture below, the client generally asks for web pages or other files (such as images).

Both HTTP Requests and Responses are made of two parts: the header and the body. Unlike protocols working at lower layers, HTTP headers do not contain addressing information, but instead, control information that will help the other device to read the request or the response. Only the first line in the header is mandatory, as it is the one containing the instructions that allow the request to be completed successfully. All the other lines contain extra parameters that allow fine-tuning of the HTTP operation. These parameters are always written in form of Parameter: Value, one per line, so there is no need to follow a specific order as the parameter being used is always specified (e.g. you can use User-Agent parameter before or after Pragma parameter without any difference). Parameters slightly differ between requests and responses, and it might come handy to know how HTTP works exactly, so let’s check two examples of HTTP headers.
HTTP Request header
The following code is an example of an HTTP Request, specifically the one made by Mozilla Firefox when you go to www.ictshore.com.
GET / HTTP/1.1
Host: www.ictshore.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: it-IT,it;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Cookie:
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Pragma: no-cache
Cache-Control: no-cache
Before diving into all the additional parameters, let’s check out the very first line. Here we can find three important items: the method (GET in this case), the subject of the request (/ here) and the HTTP Version (HTTP/1.1 here). While “HTTP Version” is pretty self-explanatory, it is worth spending some words on the subject and method. The subject is simply the name of the webpage we are trying to get, which in this case is none as we are trying to reach the home of www.ictshore.com. The method, instead, defines how we are trying to interact with the server. Three HTTP methods exist:
- GET – with this method, the client asks for a web content and all user-defined parameters are specified within the subject inside the header
- POST – with this method, the client asks for web content, all user-defined parameters are specified in the body of the request
- HEAD – this is a special method: the client asks for a web content just like a GET request, but tells the server to send back only the header in the HTTP Response, without the body – we will see later in this section what is the purpose of this method
With user-defined parameters, we do not mean extra parameters of the HTTP header, but instead application-specific items. For example, when you fill a search form and then you click the search button, you need to send to the server what you typed in the search button somehow: you do that with some kind of user-defined parameter. Now that we know the very basics of HTTP Requests, let’s check out the extra parameters in the header:
- Host – the name of the server we are trying to reach
- User-Agent – information about our browser and operating system, to be used from the server to give us the version of the webpage that works better with our system
- Accept – file formats accepted by the client
- Accept-Language – languages accepted by the client
- Accept-Encoding – encoding accepted by the client (encoding is the way text is stored in binary)
- Cookie – Cookies are variables sent from the server to the client, which then stores them. They are sent to the webserver in any new request until they expire using this field
- Connection – specifies settings about the HTTP connection
- Upgrade-Insecure-Requests – if set to 1, try to use a secure connection over a non-secure connection whenever possible
- Pragma – Tells the server information about the way the client is going to do caching (explained later in this section)
- Cache-control – Tells the server extra information about the way the client is going to do caching
After the last extra parameter in a header, to divide the header from the body, we simply use an empty line. If the request is well-structured, then the server will be able to process it and send an adequate response.
HTTP Response header
The following code shows the response to the request previously described.
HTTP/1.1 200 OK
Server: nginx/1.10.2
Date: Mon, 26 Dec 2016 10:10:21 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Cache-Control: no-cache, must-revalidate, max-age=0
Link: ; rel="https://api.w.org/"
Vary: Accept-Encoding
Content-Encoding: gzipAgain, the first line is the mandatory one. It contains two important information, the HTTP Version (HTTP/1.1 here) and the status of the request, which is written using a code (200 here) and then in plain-text (OK here). In this case, the request was successful as the returned status code is 200 OK. It is extremely useful to know the principles behind HTTP Codes, so check out the following table.
| Code | Name | Description |
|---|---|---|
1XX | Informational | This response contains extra information and precedes a normal HTTP response. |
2XX | Successful | The server was able to correctly respond to the request. |
3XX | Redirection | The content is somewhere else, informing the client to reach the content at the new location. |
4XX | Client Error | The server was unable to respond to the request because of a mistake of the client (e.g. the client made a request with a bad format). |
5XX | Server Error | The server is aware that it cannot respond to the request |
Most common HTTP status codes include 200 OK, 404 Not Found and 501 Internal Server Error. To have a complete and always updated list of these codes please refer to this document of the World Wide Web Consortium (w3c). Now it is time to check out the extra-parameters generally used in HTTP Response.
- Server – an application used by the server to respond to the request (webserver)
- Date – Date when the content was last modified
- Content-Type – what is the content in the body of the response
- Transfer-Encoding – extra settings about the encoding
- Connection – extra settings about the HTTP connection
- Pragma – Tells the client whether it should cache the content or not
- Expires – When the content sent to the client with this response will become invalid
- Cache-Control – Tells additional information to the client about caching
- Link – information about linking
- Vary – accept variation from the client on the parameters specified there
- Encoding – encoding used in the body of this response
Now, the Expires and Date parameters allow us to understand the HEAD method of HTTP Requests. That method has been developed to enhance the performance of caching. When a browser visits a website, it can store all the HTTP Responses it receives locally so that when you check that website again you will see the locally stored content without having the web-server to send you that content again. However, what happens if the content changes? You keep seeing the local copy of the content, which is now old. Instead, with the HEAD method, you ask for the HTTP header for the content and you can check if the date changed. If the data is changed, the client will then craft a new request (GET or POST) to get the updated content. The Expires field, instead, tells when this content – if cached – will become invalid. As you can see, in the modern system it is set to dates in the past so that nothing is cached: the original purpose of caching was to save bandwidth and speed-up the connection, but on high-bandwidth and high-speed modern links we tend to opt for always up-to-date content, so caching is rarely used.
Complete HTTP Operation
At this point, you might think that you make an HTTP Request to get a webpage and you receive a Response containing the webpage itself, then you are done. Not so easy! Websites are content-rich elements, they contain images, videos, fancy fonts, Flash scripts, and many other items. You start with a single request, then you get a text-based webpage that contains references to other content. Basically, on the webpage, you get you will find instructions like “Okay, put there: image X” or “Please use font Y”. Your browser read these instructions, and then query the server for missing files using a new HTTP Request. For each file, there is an independent HTTP Response, as in the picture.
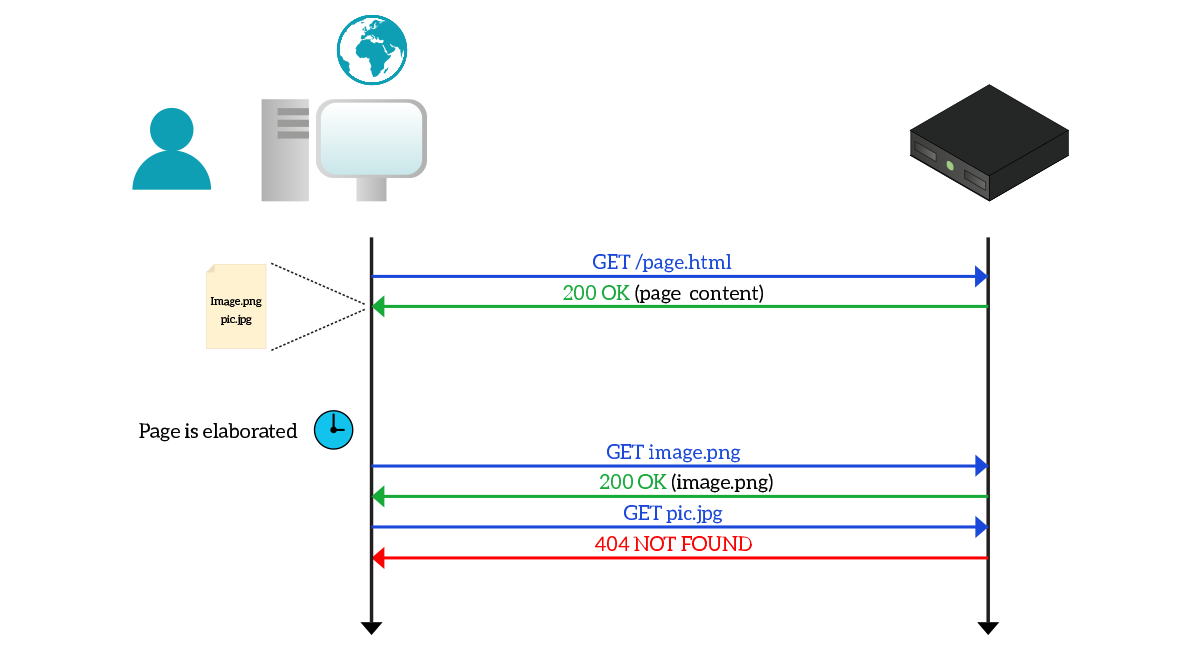
Generally, a TCP connection supports a single exchange of requests and responses, but to speed up the process some systems may implement several requests and responses over the same TCP connection or may open several simultaneous TCP/HTTP connections, one per file, to get everything faster.
Secure HTTP
Security is a key topic in modern networking, so we cannot talk about the web without spending some time on HTTPS. This protocol is the secure version of HTTP (The “S” stands for “Secure”) because it authenticates the server and encrypts the traffic. This means that the client knows without any doubt that it is talking to the correct server, and the traffic between the client and server cannot be listened to by anyone else. HTTPS works on TCP port 443 (server-side).

Normal HTTP traffic can be manipulated by an attacker easily, as it is just plain text. HTTPS traffic is still plain text, but it uses an additional layer of security at the Transport Layer, named TLS (Transport Layer Security). TLS is the new version of SSL (Secure Socket Layer), and it is an enhancement to TCP connections that encrypt the traffic. Basically, the web application writes plain text as usual, but that text is encrypted while going down the OSI stack. On the other device, it will be decrypted while going up.
Mail Protocols
Emails are a great way to communicate over the Internet. They allow the exchange of text-based and media-rich content, such as images, videos, and any other file. All of that is delivered almost immediately to the correct receiver, and this makes emailing a must-have component for any business. Unlike the web, which works with a single protocol, there are several protocols involved in the email exchange (sending and receiving emails).
Any email system relies on servers. An email server is simply a server that is ready to receive emails and store them 24/7 in a mailbox, waiting for a user to log in and check them. That server is also the one that sends emails on your behalf to other servers. To send emails, we use the Simple Mail Transfer Protocol (SMTP). This is a text-based TCP protocol working over TCP transport on port 25 (server-side) that has a specific purpose: deliver mails to the destination server. Any time you send an email, you send it to your email server using SMTP. Then, your server checks all the recipients and send the emails to all the destination servers. At this point, the email will be stored there until the user checks his inbox.
To manage the emails you have in your inbox, you can use two protocols: Post Office Protocol (POP), currently used in version 3 – POP3, or Internet Message Access Protocol (IMAP). POP3 (port 110 server-side) is considered to be legacy because it just downloads your inbox, deleting it from the server. This means that you cannot see the same emails on multiple devices, because the first one to see them will download them and delete them from the server. Instead, to use multiple devices, you should use IMAP (port 143 server-side). With this protocol, you work on your emails using a temporary local copy, while the masterpiece is always kept on the server. More than that, IMAP adds the possibility to organize your emails in folders even in the server.
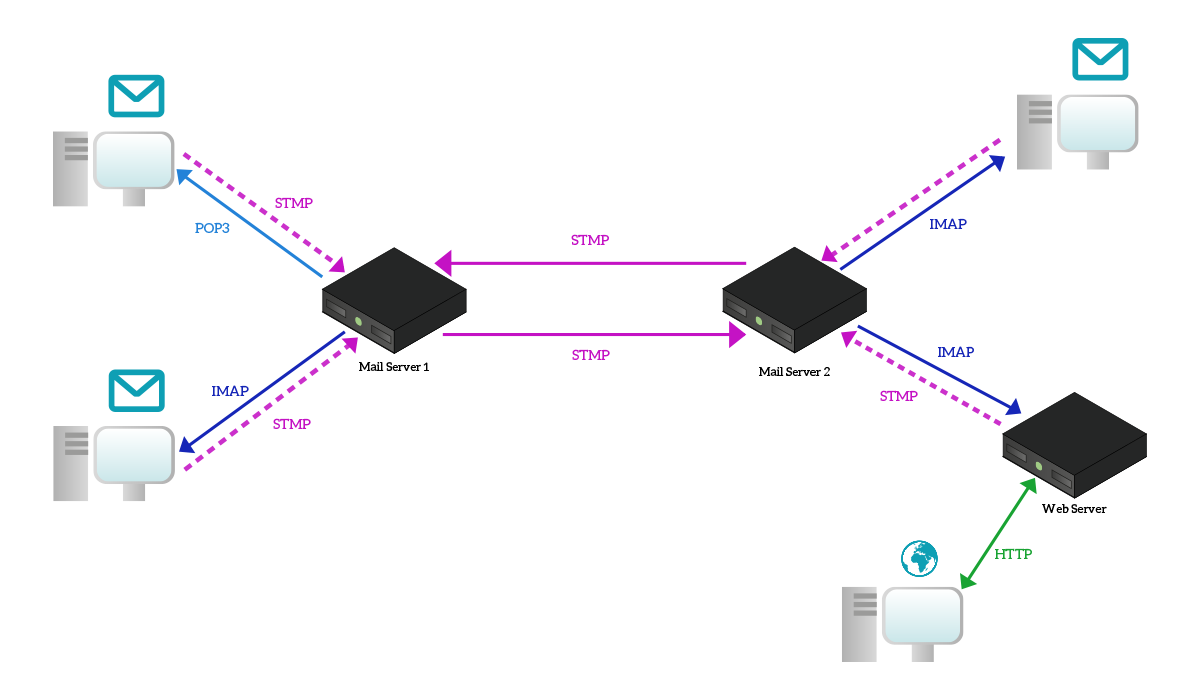
Another important consideration is webmails, mailboxes you can access using your browser in HTTP, without using neither SMTP, IMAP or POP3. This is because someone created a web application (basically a website) that interact with the mail server using the right protocols and then provides an interface to the user over HTTP. Many email providers offer the possibility to check your inbox using the traditional protocols, but they also give you an easy web interface. In the previous picture, we have an example, where the user connects to a web server instead of a mail server to check his emails.
Controlling Remote Devices
Any company needs an IT infrastructure, which grows bigger as the company grows. That infrastructure is going to be full of different devices: network devices such as switches and routers, and infrastructure servers such as mail servers. In large environments, it is necessary to have the possibility to connect to these devices and control them remotely, without having to physically go where they are. Fortunately, our protocol suite provides us with two technologies and several protocols to do just that.
Remote Desktop
The “Remote Desktop” protocol family is the group of protocols that allows you to control devices using the same graphical interface you use when you are physically in front of the device. You establish a session with the remote device, then your PC is going to intercept everything you do and send it to the remote device. This means that it will send everything you type on the keyboard, the movements of the mouse, and even the connection of USB drives. Instead, the remote device is going to send you video and audio outputs.

There are two main protocols in this family: Remote Desktop Protocol (RDP) created by Microsoft and using TCP port 3389, and PC over IP (PCoIP) created by VMware. They are used mainly to manage Windows servers and in Virtual Desktop Infrastructure (VDI) environments. Basically, in a VDI environment, you just use your computer to connect to a remote virtual PC, then you use that remote Virtual PC as if it was yours. We won’t go any further on that, as it is out of scope for this article.
Remote Shell
Not all devices have a graphical interface: some of them have just a text interface, named Shell, where you can simply type text and see text in return, you cannot even use the mouse! This type of user interface is extremely lightweight (do not consume a lot of computational resources) and its control can be automated because it is easier for an automated script to send a simple text than to emulate mouse movement.
Devices with scarce resources, legacy devices, network devices, and Linux servers offer a remote shell interface. That interface can be delivered using two protocols: Telnet or Secure Shell (SSH). Telnet is an extremely simple protocol, but it can be extremely useful: it just opens a TCP connection to the remote device (by default on port 23) and then send everything you type on it. Since all application protocols are text-based, you can telnet-in a web server opening a connection to port 80, then manually craft an HTTP Request. You can instead use port 23 to send commands to control and configure the remote device. Note that, even if the remote device asks you to authenticate, the username and password you provide are sent in plain-text, so an attacker in the middle could see your personal data.
A much better alternative to Telnet is SSH (server-side TCP port 22). The user experience is almost identical, but it offers a great level of security because it encrypts traffic in both directions. Since you can change the configuration of devices using remote shell protocol, it is best to configure those devices to accept only SSH connection as Telnet can be spoofed – an attacker gaining access to your devices could seriously harm your infrastructure.
File Transfer
We cannot talk about application protocols without talking about File Transfer Protocol (FTP). The name is self-explanatory, FTP allows the exchange of files between a client and a server, but also the possibility to list files on the remote device: all in all, it is a way to control a remote file system.
FTP works with two separate TCP connections, one to be used for control and one to be used for data. The control connection (port 21 server-side) is the one used to exchange instructions (e.g. “Get me this file!”), while the data connection (port 20 server-side) is the one used to physically transfer files.
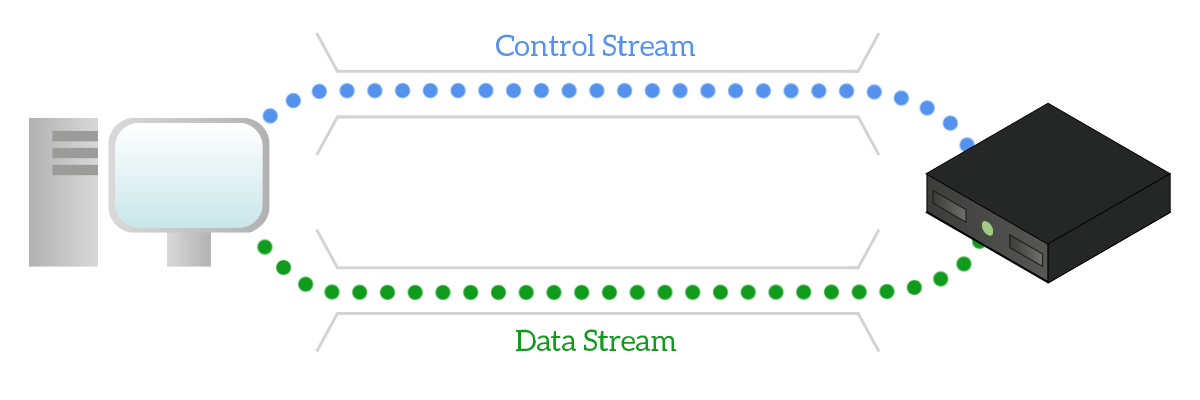
There are two ways a TCP connection can be opened: active or passive. With active FTP, the client opens the control connection and then send over it the “PORT” command, specifying on which port it will be listening for the data connection. The server reads that information and then actively opens the data connection to the client on the port specified. With passive FTP, instead, the client opens the control connection and send over it the “PASV” (Passive) command. The server then understands that the client is trying an FTP connection and sends the “PORT” command to the client to tell it on which port it will be listening for data. Then, it is the client to open the data connection toward the server on the specified port.
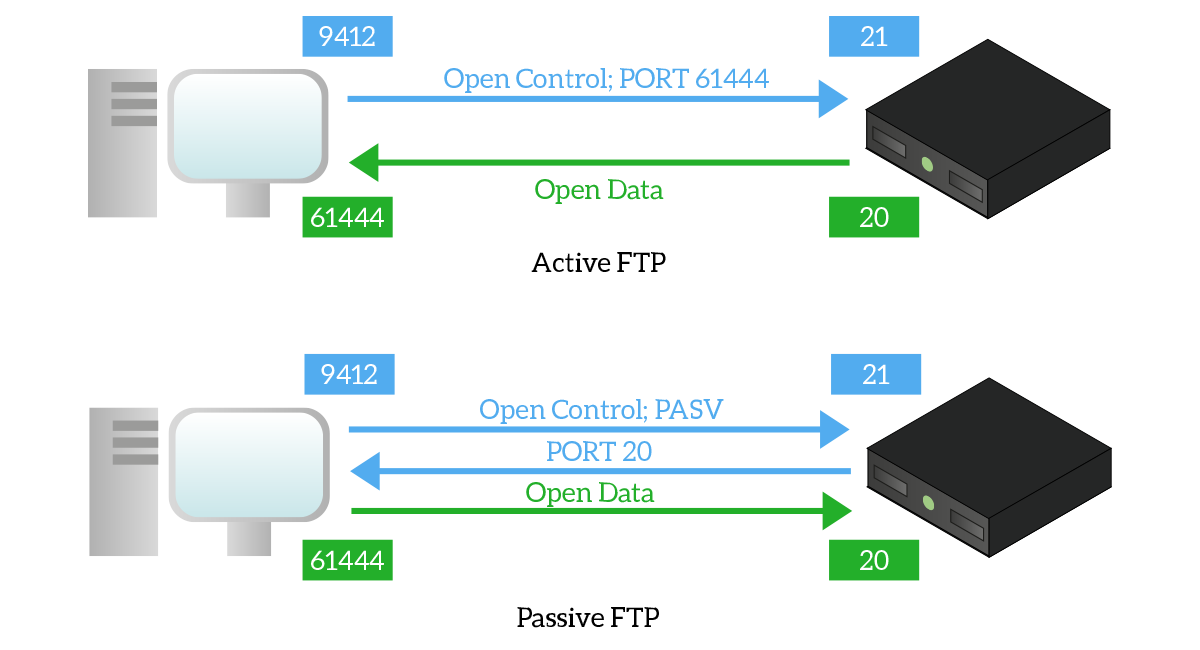
Active FTP is the simpler configuration, but passive FTP is the one to be used the majority of times. Even if passive FTP involves a more sophisticated exchange, in this connection it is the client to open both control and data connection and this can be extremely useful when the client is protected by a firewall, as it is in most scenarios. Generally, firewalls are configured to allow clients to connect to external devices, but any connection initiated from external devices toward clients is denied: this will prevent the server from opening the data connection. If the client is the one opening all the connections, it will be permitted by the firewall.
Conclusion
Just to recap, the following table lists all the protocols we covered in this article with the key details you should remember.
| Protocol | Transport | Default Server Port | Description |
|---|---|---|---|
| HTTP | TCP | 80 | Transfer web content without encryption. |
| HTTPS | TCP | 443 | Transfer web content securely (with encryption). |
| SMTP | TCP | 25 | Send emails. |
| POP3 | TCP | 110 | Download emails from a mail server. |
| IMAP | TCP | 143 | Manage emails on the mail server. |
| RDP | TCP | 3389 | Run a remote desktop session (with graphic interface) on another PC. |
| Telnet | TCP | 23 | Send commands to a shell-based device, without encryption. |
| SSH | TCP | 22 | Send commands to a shell-based device, with encryption. |
| FTP | TCP | 21, 20 | Transfer file between a client and a server. |
With this knowledge in mind, you should have now a general idea about how the application layer works. With that in mind, you are ready to face some specific application layer protocols that are used to enhance the functionalities of the network, as we will see in the next article in the course.

